Event Loop NodeJS: Um Guia Completo Para Iniciante

A assincronia em qualquer linguagem de programação é difícil e o event loop vem pra resolver isso. Conceitos como simultaneidade, paralelismo e deadlocks fazem tremer até os engenheiros mais experientes. O código executado de forma assíncrona é imprevisível e difícil de rastrear quando há bugs. O problema é inevitável porque a computação moderna possui vários núcleos. Há um limite térmico em cada núcleo da CPU, e nada está ficando mais rápido. Isso pressiona o desenvolvedor a escrever um código eficiente que aproveite as vantagens do hardware.
JavaScript é de thread única, mas isso limita o Node de utilizar arquitetura moderna? Um dos maiores desafios é lidar com várias threads por causa de sua complexidade inerente. Criar novas threads e gerenciar a troca de contexto entre elas é caro. Tanto o sistema operacional quanto o programador devem trabalhar muito para fornecer uma solução. Neste artigo, mostrarei como o Node lida com event loop. Explorarei cada parte do event loop do Node.js e demonstrarei como ele funciona. Um dos recursos melhores recursos do Node é o event loop, porque ele resolveu um problema difícil de uma maneira inovadora
Event Loop
O event loop é um loop simultâneo de thread única, sem bloqueio e de forma assíncrona. Imagine uma solicitação web que faz uma pesquisa no banco de dados. Uma única thread só pode fazer uma coisa de cada vez. Em vez de aguardar a resposta do banco de dados, ele continua a selecionar outras tarefas na fila. No event loop, o loop principal desenrola a pilha de chamadas e não espera os retornos de chamada. Como o loop não bloqueia, é tranquilo fazer mais de uma solicitação web por vez. Várias solicitações podem ser enfileiradas ao mesmo tempo, o que as torna simultâneas. O event loop não espera que uma solicitação seja concluído, mas pega retornos de chamada conforme eles vêm, sem bloqueio.
O event loop em si é semi-infinito, o que significa que se a pilha de chamadas ou a fila de retorno de chamada estiverem vazias, ele pode sair do loop. Pense na pilha de chamadas como um código síncrono que se desenrola, como console.log, antes que o loop busque mais trabalho. O Node usa libuv por baixo dos panos para pesquisar no sistema operacional em busca de retornos de chamada de conexões de entrada.
Você pode estar se perguntando, por que o event loop é executado em uma única thread? Threads são relativamente pesados na memória para os dados de que necessita por conexão. Threads são recursos do sistema operacional que aumentam e isso não é escalonável para milhares de conexões ativas.
Vários tópicos em geral também complicam a história. Se um retorno de chamada retornar com dados, ele deve empacotar o contexto de volta para a thread que está em execução. A troca de contexto entre threads é lenta, porque deve sincronizar o estado atual, como a pilha de chamadas ou variáveis locais. O event loop elimina os bugs quando várias threads compartilham recursos, porque é thread única. Um loop de thread única corta casos extremos de segurança de thread e pode mudar de contexto muito mais rápido. Este é o verdadeiro lance por trás do event loop. Ele faz uso efetivo de conexões e threads enquanto permanece escalável.
Loop Semi-infinito
A maior pergunta que o event loop deve responder é se o loop está ativo. Em caso afirmativo, ele descobre quanto tempo deve esperar na fila de retorno de chamada. A cada iteração, o loop desenrola a pilha de chamadas e, em seguida, pesquisa.
Aqui está um exemplo que bloqueia o loop principal:
setTimeout(
() => console.log('Oi a fila de retorno'),
5000); // Mantenha o loop ativo por x tempo
const stopTime = Date.now() + 2000;
while (Date.now() < stopTime) {} // Bloqueie o loop principal
Se você executar este código, observe que o loop fica bloqueado por dois segundos. Mas o loop permanece ativo até que o retorno de chamada seja executado em cinco segundos. Depois que o loop principal é desbloqueado, o mecanismo de pesquisa descobre quanto tempo ele espera nos retornos de chamada. Esse loop termina quando a pilha de chamadas é desfeita e não há mais retornos de chamada restantes.
A fila de retorno de chamada
Agora, o que acontece quando eu bloqueio o loop principal e agendo um retorno de chamada? Uma vez que o loop é bloqueado, ele não coloca mais callbacks na fila:
const stopTime = Date.now() + 2000;
while (Date.now() < stopTime) {} // Bloqueie o loop principal
// Isso leva 7 segundos para ser executado
setTimeout(() => console.log('Executou callback A'), 5000);
Desta vez, o loop permanece ativo por sete segundos. O event loop é burro em sua simplicidade. Ele não tem como saber o que pode ser colocado na fila no futuro. Em um sistema real, os retornos de chamada de entrada são enfileirados e executados, pois o loop principal está livre para pesquisar. O event loop passa por várias fases sequencialmente quando é desbloqueado. Portanto, para vencer aquela entrevista de emprego sobre o loop, evite jargões sofisticados como “emissor de evento” ou “padrão de reator”. É um humilde loop de thread único, simultâneo e não bloqueador, não precisa querer complica, lembre-se o simples é poderoso.
O Event Loop assíncrono / espera
Para evitar o bloqueio do loop principal, uma ideia é envolver a E / S síncrona em torno do recurso async / await. Caso esteja procurando um bom curso / treinamento de NodeJS te recomendo esse aqui.
const fs = require('fs');
const readFileSync = async (path) => await fs.readFileSync(path);
readFileSync('readme.md').then((data) => console.log(data));
console.log('O event loop continua sem bloqueio...');
Tudo o que vier depois de await vem da fila de retorno de chamada. O código é lido como um código de bloqueio síncrono, mas não bloqueia. Note que async / readFileSync await o torna possível, o que o tira do loop principal. Pense em tudo o que vem depois await como não-bloqueador por meio de um retorno de chamada.
O código acima é apenas para fins de demonstração. Em código real, eu recomendo fs.readFile, que dispara um retorno de chamada que pode envolver uma promise. A intenção geral ainda é válida, porque isso tira o bloqueio de E / S do loop principal.
Mais detalhes sobre
E se eu dissesse que o event loop tem mais do que uma pilha de chamada e mais uma fila de retorno de chamada? E se o event loop não fosse apenas um loop, mas muitos?
Agora, quero levá-lo para trás da fachada e para visualiza com mais detalhes os componentes internos do NodeJS
Fases do Event Loop
Estas são as fases do Event Loop:

Estrutura event loop
1 . Ás datas / hora são atualizadas. O Event loop armazena em cache a hora atual no início do loop para evitar chamadas de sistema frequentes relacionadas ao tempo. Essas chamadas de sistema são internas à libuv.
2 . O loop está vivo? Se o loop tiver identificadores ativos, solicitações ativas ou identificadores de fechamento, ele está vivo. Conforme mostrado, retornos de chamada pendentes na fila mantêm o loop ativo.
3 . Os cronômetros de vencimento são executados. Este é o lugar onde o setTimeout() ou setInterval() retornos de chamada executada. O loop verifica o cache se tem callbacks ativos que expiraram em execução.
4 . Retornos de chamada pendentes na fila são executados. Se a iteração anterior adiou quaisquer retornos de chamada, eles serão executados neste ponto. O polling normalmente executa callbacks de E / S imediatamente, mas há exceções. Esta etapa lida com quaisquer retardatários da iteração anterior.
5 . Manipuladores ociosos são executados - principalmente a partir de nomenclatura inadequada, porque eles são executados a cada iteração e são internos ao libuv.
6 . Prepare identificadores para setImmediate() execução de retorno de chamada na iteração do loop. Esses identificadores são executados antes dos blocos do loop para E / S e preparam a fila para esse tipo de retorno de chamada.
7 . Calcule o tempo limite da votação. O loop deve saber quanto tempo ele bloqueia para E / S. É assim que ele calcula o tempo limite:
- Se o loop estiver prestes a sair, o tempo limite é 0;
- Se não houver identificadores ou solicitações ativas, o tempo limite será 0;
- Se houver algum identificador inativo, o tempo limite é 0;
- Se houver algum identificador pendente na fila, o tempo limite será 0;
- Se houver alguma fechamento, o tempo limite é 0;
- Se nenhuma das opções acima, o tempo limite é definido para o temporizador mais próximo ou, se não houver temporizadores ativos, infinito.
8 . O loop bloqueia para E / S com a duração da fase anterior. Os retornos de chamada relacionados a E / S na fila são executados neste ponto.
9 . Verifique a execução de callbacks do identificador. Esta fase é onde setImmediate() funciona e é a contrapartida para preparar. Quaisquer setImmediate() retornos de chamada enfileirados no meio da execução de retorno de chamada de E / S são executados aqui.
10 . Fechar callbacks são executados. Esses são identificadores ativos descartados de conexões fechadas.
11 . A iteração termina.
Você deve estar se perguntando por que a pesquisa bloqueia E / S quando deveria ser sem bloqueio? O loop bloqueia apenas quando não há retornos de chamada pendentes na fila e a pilha de chamadas está vazia. No Node, o temporizador mais próximo pode ser definido por setTimeout, por exemplo. Se definido como infinito, o loop espera nas conexões de entrada com mais trabalho. É um loop semi-infinito, porque a pesquisa mantém o loop ativo quando não há mais nada a fazer e há uma conexão ativa.
Aqui está a versão Unix deste cálculo de tempo limite é toda a sua glória C:
int uv_backend_timeout(const uv_loop_t* loop) {
if (loop->stop_flag != 0)
return 0;
if (!uv__has_active_handles(loop) && !uv__has_active_reqs(loop))
return 0;
if (!QUEUE_EMPTY(&loop->idle_handles))
return 0;
if (!QUEUE_EMPTY(&loop->pending_queue))
return 0;
if (loop->closing_handles)
return 0;
return uv__next_timeout(loop);
}
Você pode não estar muito familiarizado com C, mas parece inglês e faz exatamente o que está na fase sete.
Uma demonstração fase a fase
Para mostrar cada fase em JavaScript simples:
// 1. Loop começa, o timestamps é atualizados
const http = require('http');
// 2. O loop permanece vivo se houver código na pilha de chamadas para desenrolar
// 8. Pesquisar E / S e executar este retorno de chamada de conexões de entrada
const server = http.createServer((req, res) => {
// O retorno de chamada de E / S da rede é executado imediatamente após a pesquisa
res.end();
});
// Mantenha o loop ativo se houver uma conexão aberta
// 7. Se não houver mais nada a fazer, calcule o tempo limite
server.listen(3000);
const options = {
// Evite uma consulta DNS para ficar fora do pool de threads
hostname: '192.0.2.1',
port: 3000
};
const sendHttpRequest = () => {
// Callbacks de E / S de rede executados na fase 8
// Callbacks de E / S de arquivo executados na fase 4
const req = http.request(options, () => {
console.log('Resposta recebida do servidor');
// 9. Executar verificação de retorno de chamada
setImmediate(() =>
// 10. Feche a execução da callback
server.close(() =>
// O fim. ALERTA DE SPOILER! O Loop morre no final.
console.log('Fechando servidor')));
});
req.end();
};
// 3. O cronômetro é executado em 8 segundos, enquanto o loop permanece ativo
// O tempo limite calculado antes da votação o mantém ativo
setTimeout(() => sendHttpRequest(), 8000);
// 11. Fim da iteração..
Como os callbacks de E / S de arquivo são executados na fase quatro e antes da fase nove, espere setImmediate() disparar primeiro:
fs.readFile('leiame.md', () => {
setTimeout(() => console.log('Arquivo I/O callback via setTimeout()'), 0);
// Este retorno de chamada é executado primeiro
setImmediate(() => console.log('Arquivo I/O callback via setImmediate()'));
});
A E / S de rede sem uma pesquisa de DNS é menos cara do que a E / S de arquivo, porque é executada no event loop principal. Em vez disso, a E / S do arquivo é enfileirada por meio do pool de threads. Uma pesquisa de DNS também usa o pool de threads, então isso torna a E / S de rede tão cara quanto a E / S de arquivo.
Pool de Thread - Event loop
Os componentes internos do nó têm duas partes principais: o mecanismo JavaScript V8 e o libuv. E / S de arquivo, pesquisa de DNS e E / S de rede acontecem via libuv.
Esta é a arquitetura geral:
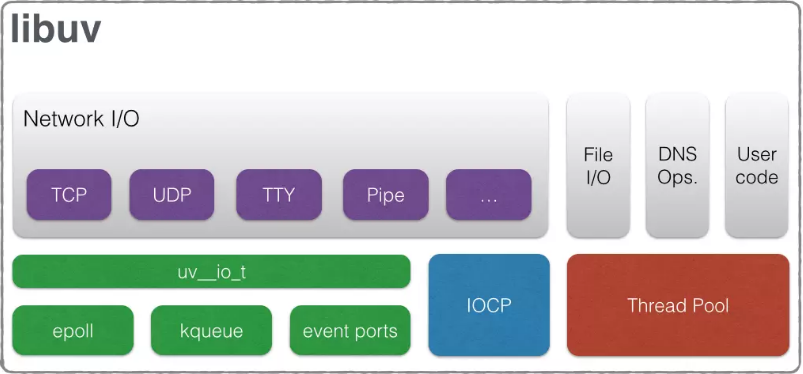
Fonte da imagem: documentação do libuv
Para E / S de rede, o event loop pesquisa dentro do encadeamento principal. A thread não é segura para threads porque não muda de contexto com outro thread. A E / S de arquivo e a pesquisa de DNS são específicas da plataforma, portanto, a abordagem é executá-los em um pool de threads. Uma ideia é fazer a pesquisa de DNS você mesmo para ficar fora do pool de threads, conforme mostrado no código acima. Colocar um endereço IP versus localhost, por exemplo, tira a pesquisa do pool. O pool de threads tem um número limitado de threads disponíveis, que pode ser definido por UV_THREADPOOL_SIZEmeio da variável de ambiente. O tamanho do pool de threads padrão é cerca de quatro.
O V8 é executado em um loop separado, esvazia a pilha de chamadas e devolve o controle ao event loop. O V8 pode usar vários encadeamentos para coleta de lixo fora de seu próprio loop. Pense no V8 como o mecanismo que recebe JavaScript bruto e o executa no hardware.
Para o programador médio, o JavaScript permanece com thread único porque não há segurança de thread. V8 e libuv internos giram seus próprios threads separados para atender às suas próprias necessidades.
Se houver problemas de taxa de transferência no Node, comece com o event loop principal. Verifique quanto tempo leva para a aplicação concluir uma única iteração. Não deve durar mais do que cem milissegundos. Em seguida, verifique se há inanição do pool de encadeamentos e o que pode ser despejado do pool. Também é possível aumentar o tamanho do pool por meio da variável de ambiente. A última etapa é fazer um microbenchmark do código JavaScript no V8 que é executado de forma síncrona.
Empacotando
O event loop continua a iterar em cada fase à medida que os retornos de chamada são enfileirados. Mas, dentro de cada fase, há uma maneira de enfileirar outro tipo de retorno de chamada.
process.nextTick() vs setImmediate()
No final de cada fase, o loop executa o process.nextTick() retorno de chamada. Observe que esse tipo de retorno de chamada não faz parte do event loop porque é executado no final de cada fase. O setImmediate() retorno de chamada faz parte do loop geral de eventos, portanto, não é tão imediato quanto o nome indica. Como process.nextTick() precisa de conhecimento avançado de event loop clique aqui caso queira ir para o próximo nível em nodejs, recomendo o uso setImmediate() em geral.
Existem alguns motivos pelos quais você pode precisar process.nextTick():
- Permita que a E / S da rede lide com erros, limpe ou tente a solicitação novamente antes que o loop continue;
- Pode ser necessário executar um retorno de chamada após o desenrolar da pilha de chamadas, mas antes que o loop continue.
Digamos, por exemplo, que um emissor de evento deseja disparar um evento enquanto ainda está em seu próprio construtor. A pilha de chamadas deve ser desenrolada antes de chamar o evento.
const EventEmitter = require('eventos');
class ImpatientEmitter extends EventEmitter {
constructor() {
super();
// Acione isso no final da fase com uma pilha de chamadas desfeita
process.nextTick(() => this.emit('eventos'));
}
}
const emitter = new ImpatientEmitter();
emitter.on('event', () => console.log('Ocorreu um evento impaciente!'));
Permitir que a pilha de chamadas seja desenrolada pode evitar erros como RangeError: Maximum call stack size exceeded. Uma pegadinha é ter certeza de process.nextTick()que não bloqueia o event loop O bloqueio pode ser problemático com chamadas de retorno de chamada recursivas na mesma fase.
Conclusão
O event loop é a simplicidade em sua sofisticação final. É preciso um problema difícil, como assincronia, segurança de thread e simultaneidade. Ele remove o que não ajuda ou o que não precisa e maximiza o rendimento da maneira mais eficaz possível. Por causa disso, os programadores de Node gastam menos tempo com bugs assíncronos e mais tempo entregando novos recursos.
